The ZIP File Format
This is a technical overview of the binary format of ZIP files for programmers or other technical readers.
The scope of this text is the ZIP file format itself, not the optional compression or encryption algorithms. After reading this text you should have enough information to be able to read and write ZIP files byte by byte.
Overview
The ZIP file consists of several headers. Each header is identified by a signature followed by header data.
The headers are:
- Local file header - Contains metadata about a single file and is followed by the file data. Each file can be compressed and encrypted independently.
- Central directory file header - Contains metadata about a single file and an offset to the Local file header for that file. A list of these headers forms the Central directory which can be used to quickly enumerate all files in the archive.
- End of central directory record - Contains information on where to find the first central directory file header.
This is a visualization of a ZIP file containing a.txt and b.txt:
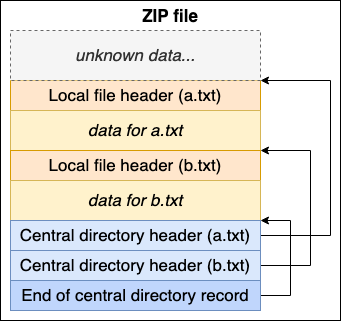
The reason for the central directory being at the bottom is that we can overwrite it by just appending a new central directory.
If we want to add a file, c.txt, we can append a new file record and a new central directory that includes it:
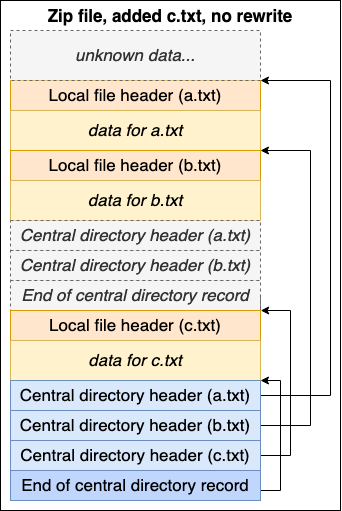
The old central directory remains in the file data, but is no longer referenced. With this approach, we have managed to append data to the archive without rewriting the entire file.
This behavior was especially important when floppy disks were used for storage. Writes were slow and ZIP archives could span multiple disks.
You can do more than just adding files without rewrites, you can also modify and delete files in an archive by just appending data. A deleted file and the previous version of a modified file will of course remain on disk, but they will not be read by a compliant ZIP reader.
This is how you can achieve modification and deletion in the "ZIP file" example above, by only appending new data:

Since a ZIP file is read from the end, anything can be put at the start of the ZIP file. You can for example make a file that is both a valid PNG and a valid ZIP (polyglot) to hide a ZIP archive inside a file that looks and works like an image.
If you decide to write your own ZIP extractor after this article, you can also append your ZIP file to your ZIP extractor binary and make it unzip itself when executed. This is called a self-extracting archive and is a common technique for auto unzipping when you double click the file.
The ZIP format allows “comments” to be put at several places in the file. These comments can store arbitrary data to make the ZIP file compatible with more than just the ZIP format.
Multi-Part/Multi-Disk ZIP Archive
The ZIP format allows for an archive to be split into multiple files. This was invented in a time where storage mediums had a rather limited capacity. A floppy disk could only store a couple of megabytes. Splitting the archive allowed the ZIP file to span over multiple disks.
This feature can still be useful today to circumvent file size limitations when uploading or emailing bigger archives.
The specification mentions fields called “disk number” etc, you can think of this as “file number” when working with multi-part archives. In this article, we just work with single file archives so you can always assume those fields are “disk 0”.
Reading a ZIP File
Now lets look at how to read the actual bytes of a ZIP file. All multi byte numbers are stored in little-endian.
Find the End of Central Directory Record
To read a ZIP file we must first find the End of central directory record (shortened EOCD) at the end of the file. This sounds trivial, but can be a bit tricky.
This is the definition of the EOCD:
Bytes | Description
------+-------------------------------------------------------------------------
4 | Signature (0x06054b50)
2 | Number of this disk
2 | Disk where central directory starts
2 | Numbers of central directory records on this disk
2 | Total number of central directory records
4 | Size of central directory in bytes
4 | Offset to start of central directory
2 | Comment length (n)
n | Comment
The last line in the definition is what makes finding it a bit tricky. The record has dynamic length.
Depending on the comment length, the start of the EOCD will be at different offsets from the end of file. And we can only find the comment length by reading the EOCD, so we are in a catch 22.
- If n=0 (empty comment), the EOCD starts at 22 bytes from the end
- If n=0xffff (max length comment), the EOCD starts at 22 + 0xffff = 65557 bytes from the end
The interval where the EOCD signature may exist is between 65557 and 18 from the end. That is a total of about 65.5 kb. That is not much on a modern computer so we can read that whole interval into a buffer and scan it backwards to find the signature.
When the EOCD signature is found, the hardest part of reading the ZIP is done. The rest is just parsing predefined binary structures at specific offsets.
Reading the Central Directory
From the EOCD we know the offset where the central directory starts, and how many records there are. So we just need to seek to that offset and start reading the central directory file headers.
Each central directory file header looks like this:
Bytes | Description
------+-------------------------------------------------------------------------
4 | Signature (0x02014b50)
2 | Version made by
2 | Minimum version needed to extract
2 | Bit flag
2 | Compression method
2 | File last modification time (MS-DOS format)
2 | File last modification date (MS-DOS format)
4 | CRC-32 of uncompressed data
4 | Compressed size
4 | Uncompressed size
2 | File name length (n)
2 | Extra field length (m)
2 | File comment length (k)
2 | Disk number where file starts
2 | Internal file attributes
4 | External file attributes
4 | Offset of local file header (from start of disk)
n | File name
m | Extra field
k | File comment
This defines everything we need to know about a file, including where we can find the local file header.
Since multi-part archives, compression and encryption is outside the scope of this article, we can make the following assumptions:
- Bit flag = 0
- Compression method = 0
- Compressed size = Uncompressed size
- Disk number where file starts = 0
The CRC-32 is a checksum to detect corrupt data. This can be ignored in toy projects, but in real projects it must be verified to guarantee data integrity.
The rest of the fields should be self explanatory, except Extra field, we will get back to that one later.
Extracting a File
From the central directory we know the offset to all the files. To extract a file we start by reading the local file header that looks like this:
Bytes | Description
------+-------------------------------------------------------------------------
4 | Signature (0x04034b50)
2 | Minimum version needed to extract
2 | Bit flag
2 | Compression method
2 | File last modification time (MS-DOS format)
2 | File last modification date (MS-DOS format)
4 | CRC-32 of uncompressed data
4 | Compressed size
4 | Uncompressed size
2 | File name length (n)
2 | Extra field length (m)
n | File name
m | Extra field
Note that much of this data is duplicated in the central directory file header. Both the local and central file header contains all information you need to extract the file.
Following the local file header is the actual file data of the length specified in the compressed size field.
Since we are not working with compressed or encrypted data, the file data will be the plain text content of the files. We can extract that data by reading it and writing it to a file named as the value of the File name field.
That is all there is too it!
Extra Fields
The extra field fields are there to make the ZIP format extensible. These can for example be used to add extra metadata required for certain encryption or compression algorithms.
The extra field contains a list of:
Bytes | Description
------+-------------------------------------------------------------------------
2 | Header ID
2 | Data length (n)
n | Data
One common extra field is the one with Header ID 0x5455, that is a Unix timestamp in UTC.
Another common extra field is the one with Header ID 0x0001. This is a field that contains data related to ZIP64 to allow sizes and offsets bigger than 32bit.
You can also define your own if you have a specific use case.
Conclusion
The ZIP format it self is quite simple, but extensible. It also have some interesting quirks.
To find the entry point, you have to scan for the signature 0x06054b50. However, that signature may exist in a comment or even as valid data in the EOCD record it self. To be sure you found the real EOCD signature, you likely have to follow a few offsets and validate that their signature is correct as well, otherwise go back and continue scanning.